# Working with Text
When working with NLP, there are several types of texts. Including unstructured texts, sentences or documents.
- When processing data - make sure to follow the NLP-Pipeline
# NLP-Pipeline
The common NLP-pipeline consists of 3 stages. Each stage transforms text in some way & produces another result that the next stage needs.
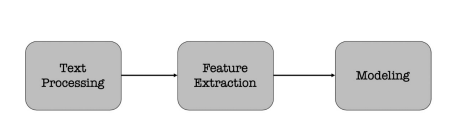
# Text Processing
First step of NLP-pipeline. Takes raw input text, cleans it, normalizes it and converts it into a form that suits for feature extraction.
There are 5 steps, you have to follow:
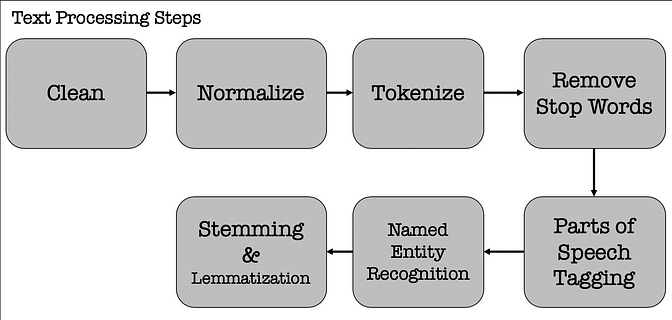
# 7 Steps - Text Processing
- Cleaning
- removing irrelevant items - HTML-tags, …
- Regex can be used
- Normalization
- converting all words to lowercase
- removing punctuation & extra spaces
- Tokenization
- split text into words (“tokens”)
- libraries used: nltk/spacy
- Stop words removal
- most common words - a, an, the, etc, … (“stop words”) are removed
- Parts of Speech Tagging
- determines each word’s grammatical category
- to find connections in phrase
- Example: “The quick brown fox jumps over the lazy dog.”
- “The” is tagged as determiner (DT)
- “quick” is tagged as adjective (JJ)
- “brown” is tagged as adjective (JJ)
- “fox” is tagged as noun (NN)
- …
- Named Entity Recognition
- recognizing named entities in data
- Example: “John Snow, CEO of John Snow Lab.”
- Person: John Snow (CEO)
- Organization: John Snow Lab
- Stemming and Lemmatization
- Stemming
- reduces word to root form - cutting off suffixes & prefixes without considering the words meaning
- approach: strip endings like “-ing”, “-ed”, or “-es”
- Example: “run”, “running”, “runner” = “run”/“runn”
- Lemmatization
- reduces word to base form - considers the word’s meaning and grammatical context
- approach: uses dictionary to find correct root form
- Example: “is, are, was, were” = “be”
- Stemming
# Feature Extraction
Is a process of transforming raw text data into a structured format that ML-algorithms can work with.
- It identifies important pieces of information (features) from the text