# spaCy ?
Is an open-source library, that can be used for NLP-tasks. It’s a really powerful library compared to the nltk-library (deprecated).
# Init
# import spacy + choose language package
import spacy
# load pretained german model into "nlp" variable (Type: Language)
nlp = spacy.load("de_core_news_sm")spacy.load loads the full pipeline:
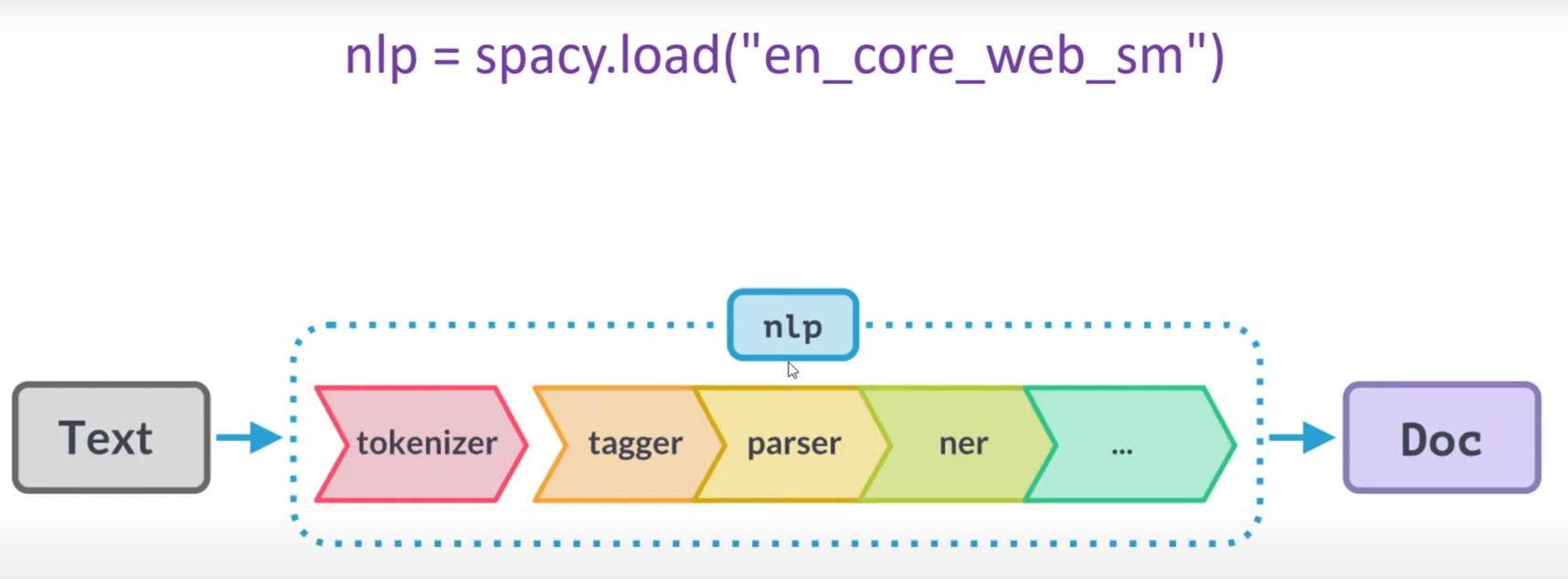
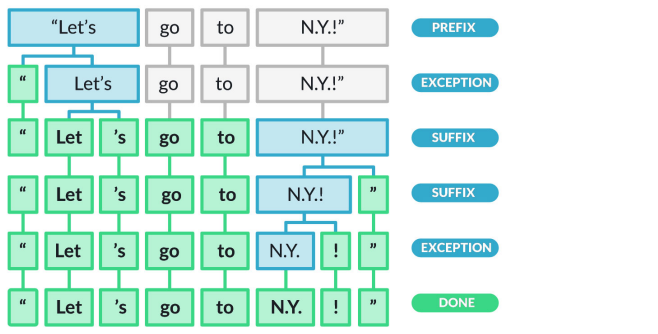
# Tokenization
# now, the doc-element is where the magic happens
doc = nlp("Dr. Strange visited Austria, because he loves Vienna.")
for token in doc:
print(token)
type(nlp)
# spacy.lang.de.German
type(doc)
# spacy.tokens.doc.Doc
type(token)
# spacy.tokens.token.Token# Removing Stopwords
Stopwords are words, that appear really often, but they are not neccessary for the sense of a sentence.
To find stopwords use the .is_stop property
# Exercise: Remove all stop-words from there
tweets=[
'This is introduction to NLP',
'It is likely to be useful, to people ',
'Machine learning is the new electrcity',
'There would be less hype around AI and more action going forward',
'python is the best tool!','R is good langauage',
'I like this book','I want more books like this'
]
# Normalizing - .lower()
df_ppl = pd.DataFrame(tweets, columns=["tweets"])
df_tweets = df_ppl["tweets"].apply(lambda x: x.lower())
for text in df_tweets:
doc = nlp(text)
for token in doc:
if not token.is_stop:
filtered_tweets.append(token)
print(token)# Part Of Speech Tagging - POS
A process of identifying words based on the “wordclass”. For example: verb, adjective, noun, …
In spacy there is the pos_ property
...
# We write on top of the stopword removal-code
for text in df_tweets:
doc = nlp(text)
for token in doc:
if not token.is_stop:
filtered_tweets.append(token)
print(f"{token.text:{40}}, {token.pos_}") …
…
Exercise: Find Nouns and Proper-Nouns of JobDescriptions
savings_list = []
with open("dataScientistJobDesc.txt", "r", encoding="UTF-8") as file:
content = file.read()
doc = nlp(content)
for token in doc:
if token.pos_ in ["NOUN", "PROPN"]:
savings_list.append(token)
print(f"{token.text:{20}}, {token.pos_}")Exercise: Count different word-classes
# POS - 3.2.2
savings_dict = {}
with open("dataScientistJobDesc.txt", "r", encoding="utf-8") as file:
content = file.read()
doc = nlp(content)
for token in doc:
if token.pos_ in savings_dict:
savings_dict[token.pos_] += 1
else:
savings_dict[token.pos_] = 1
print(savings_dict)
# Option2 - Counter
import collections from Counter
with open("dataScientistJobDesc.txt", "r", encoding="utf-8") as file:
content = file.read()
doc = nlp(content)
pos_counts = Counter(token.pos_ for token in doc)
print(dict(pos_counts)) Exercise: Find the frequently used word
with open("dataScientistJobDesc.txt", "r", encoding="utf-8") as file:
content = file.read()
doc = nlp(content)
filtered_words = [token.text.lower() for token in doc if not token.is_stop and not token.is_punct]
count_words = Counter(filtered_words)
most_counted_word, frequency = count_words.most_common()[0]
print(f"{most_counted_word}, {frequency}")# Named Entity Recognition - NER
Here, the keyword .ents is used.
...
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp('Apple is looking at buying U.K. startup for $1 billion')
for ent in doc.ents:
print(ent.text, ent.start_char, ent.end_char, ent.label_, spacy.explain(ent.label_))
Highlighting using displacy
...
from spacy import displacy
displacy.render(doc, style="ent")
Exercise: Find all people in the text.
text = "Dear Joe! I have organized a meeting with Elon Musk from Siemens for tomorrow."
doc = nlp(text)
displacy.render(doc, style="ent")
for ent in doc.ents:
if ent.label_ == "PERSON":
print(ent.text)Also with the token class you can access entity-informations:
...
for token in doc:
print(f"{token.text:10}, {token.ent_iob_}, {token.ent_type_}")