# BeautifulSoup ?
A powerful library, that allows scraping data from websites using python.
# Intro
import urllib.request as urllib2
from bs4 import BeautifulSoup# loading website
response = urllib2.urlopen('https://www.htlkrems.ac.at')
html_doc = response.read()
# represents full HTML-document
soup = BeautifulSoup(html_doc, 'html.parser')
# formated HTML-document structure
strhtm = soup.prettify()
# output
print(strhtm[:1000])Output
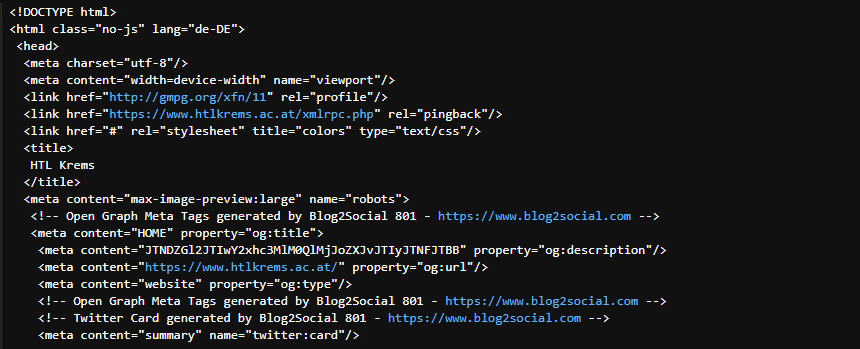
# Element data
# get element-data
print(soup.title)
print(soup.title.string)
# <title>HTL Krems</title>
# HTL Krems# .find_all()
# text from every anchor-tag on website
for tag in soup.find_all("a"):
print(tag.text)# count all hyperlinks of the website
links = soup.find_all("a")
print(len(links))