0.1
Erstellen Sie das Jupyter-Notebook (JN) 00-WarmingUp und laden Sie das referenzierte Movie-Dataset. Über welche Dimensionalität verfügt das Movie-Dataset bzw. das erstellte DataFrame?
import pandas as pddf_movies = pd.read_csv("movie.csv");df_movies.shape# dimension: (4916, 28)
0.2
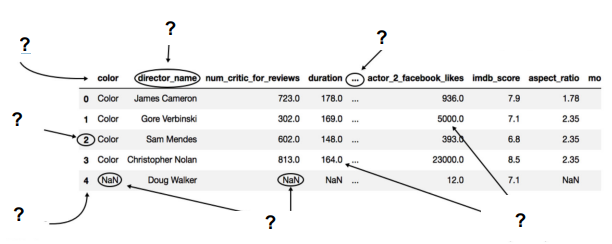
Generieren Sie nachfolgende JN-Ausgabe. Anm.: Die vielen Fragezeichen können ignoriert werden.
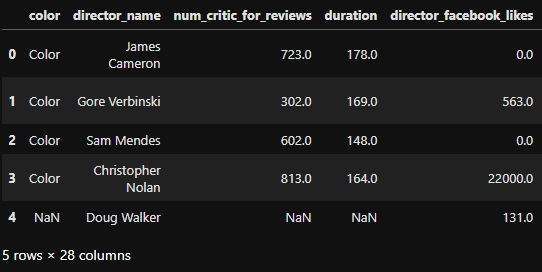
df_movies.head()# df_movies.head(5)
0.3
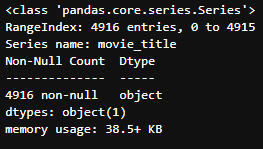
Selektiert man eine Spalte (z.B. movie_title) des erstellten Movie-DataFrames, ist das Ergebnis vom Typ Series. Treten Sie den Beweis an!
title = df_movies[movie_title]type(title)
0.4
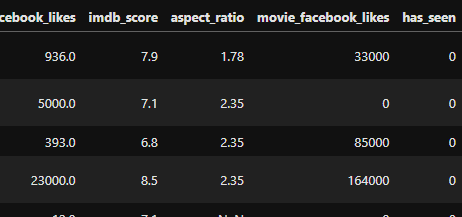
Sicherlich wissen Sie noch, dass man DataFrames manipulieren kann. Fügen Sie die Spalte „has_seen“ mit dem Initialwert „0“ hinzu.